Extract table data from image
Image
As I explained in my previous post, Extract CSV from tables in PDF, tabula-py only works with text-based PDF. If you need to extract table data from an OCR-based PDF, you will have to find another way.
So, I will introduce how to extract data from a table in an image using img2table. Unlike text-based images, it is not possible to extract characters with complete accuracy. However, in some cases, this may be sufficient.
img2table
img2table is a useful library that can automatically detect tabular data from images and output them as Python objects, Excel files, or CSV files. It is ideal for extracting data from scanned images and screenshots, as it can detect tables in images and extract text in a single process.
img2table can use multiple OCR tools such as Tesseract and PaddleOCR. So, please check READ.md for information on which OCR tools can be used.
Tools and environment
First, install the following libraries to get ready.
pip install img2table opencv-python-headless pandas
- img2table: A library for extracting table data from images.
- opencv-python-headless: OpenCV for image processing. Useful when you don't use a GUI.
- pandas: A library for processing the extracted data as a data frame.
Also, to use Tesseract, please install following:
#sudo yum install leptonica tesseract
Extract table data from an image
In this article, we will extract the data from table_eng.jpg.
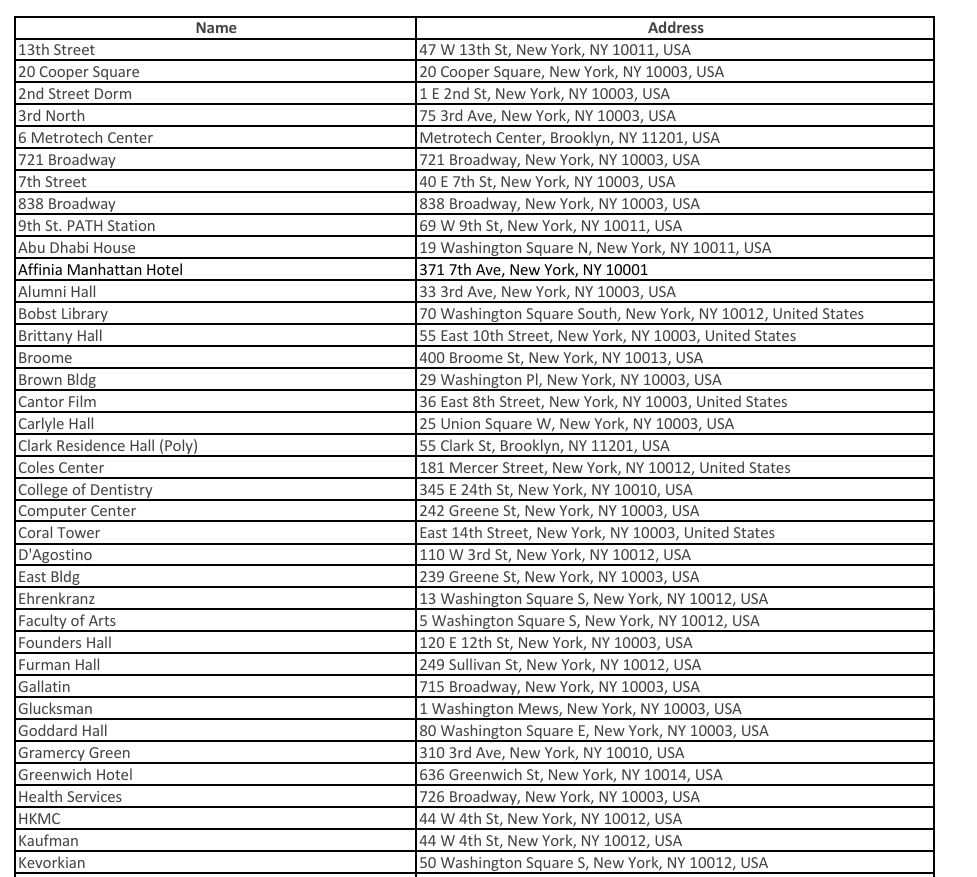
The following code will extract this table data in pandas Dataframe format.
import cv2
from img2table.ocr import TesseractOCR
from img2table.document import Image
import io
import os
os.environ['TESSDATA_PREFIX'] = '/usr/share/tesseract/tessdata/'
src = "./images/table_eng.JPG"
def preprocess(image):
# gray scale
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# threshold
_, image = cv2.threshold(image, 150, 255, cv2.THRESH_BINARY)
# resize
#image = cv2.resize(image, None, interpolation = cv2.INTER_AREA, fx=2, fy=2)
# noise
# image = cv2.medianBlur(image, 1)
return image
image = cv2.imread(src)
image = preprocess(image)
# Convert cv2 image to byte array
_, encoded_image = cv2.imencode('.png', image)
doc = Image(io.BytesIO(encoded_image.tobytes()))
ocr = TesseractOCR(n_threads=1, lang="eng")
# Table extraction
extracted_tables = doc.extract_tables(ocr=ocr,
implicit_rows=False,
implicit_columns=False,
borderless_tables=False,
min_confidence=50)
for table in extracted_tables:
print(table.df)
In preprocess, some code lines are commented out. Applying all of them reduces accuracy, so this time we adopted gray scale and threshold. Depending on the quality of the image, more preprocessing may be required.
The result is as follows:
0 1
0 Name Address
1 13th 47 W 13th St, New York, NY 10011, USA
2 20 Cooper Square 20 Cooper Square, New York, NY 10003, USA
3 2nd Street Dorm LE 2nd St, New York, NY 10003, USA.
4 3rd North 75 3rd Ave, New York, NY 10003, USA.
5 6 Metrotech Center Metrotech Center, Brooklyn, NY 11201, USA
6 721 Broadway [721 Broadway, New York, NY 10003, USA
7 7th Street [40 E 7th St, New York, NY 10003, USA
8 838 Broadway [838 Broadway, New York, NY 10003, USA
9 9th St. PATH Station 69 W 9th St, New York, NY 10011, USA
10 [Abu Dhabi House 19 Washington Square N, New York, NY 10011, USA
11 Manhattan Hotel 371 7th Ave, New York, NY 10001.
12 [Alumni Hall 33 3rd Ave, New York, NY 10003, USA.
13 Bobst Library 70 Washington Square South, New York, NY 10012...
14 Brittany Hall [55 East 10th Street, New York, NY 10003, Unit...
15 Broome. 400 Broome St, New York, NY 10013, USA
16 Brown Bldg. 29 Washington Pl, New York, NY 10003, USA
17 Cantor Film 36 East Street, New York, NY 10003, United States
18 [Carlyle Hall 25 Union Square W, New York, NY 10003, USA.
19 [Clark Residence Hall 55 Clark St, Brooklyn, NY 11201, USA
20 Coles Center 181 Mercer Street, New York, NY 10012, United ...
21 [College of Dentistry 345 E 24th St, New York, NY 10010, USA
22 [Computer Center 242 Greene St, New York, NY 10003, USA,
23 [Coral Tower East 14th Street, New York, NY 10003, United S...
24 D'Agostino 110 W 3rd St, New York, NY 10012, USA.
25 East Bldg [239 Greene St, New York, NY 10003, USA,
26 None 13 Washington Square $, New York, NY 10012, USA.
27 Faculty of Arts [5 Washington Square S, New York, NY 10012, USA
28 Founders Halll 120 12th St, New York, NY 10003, USA
29 [Furman Hall 249 Sullivan St, New York, NY 10012, USA.
30 Gallatin 715 Broadway, New York, NY 10003, USA
31 Glucksman 1 Washington Mews, New York, NY 10003, USA
32 Goddard Hall 80 Washington Square E, New York, NY 10003, USA
33 Gramercy Green 310 3rd Ave, New York, NY 10010, USA
34 Greenwich Hotel 636 Greenwich St, New York, NY 10014, USA
35 Health Services Broadway, New York, NY 10003, USA
36 HKMC 44 W 4th St, New York, NY 10012, USA
37 Kaufman 44 W 4th St, New York, NY 10012, USA
38 Kevorkian [50 Washington Square New York, NY 10012, USA
As you can see, there is an unnecessary character "[", there is a period (.) after USA, and "1E" is recognized as "LE". There seems to be room for improvement.
Improvement
There seems to still be room for improvement.
- Image quality: Blurry or low-resolution tables can reduce OCR accuracy. It is recommended to use images of the highest quality possible.
- Table complexity: Tables that span multiple pages or have complex layouts can be difficult to extract. Accuracy can be improved by utilizing Img2Table's preprocessing and customization features.
- Preprocessing: Preprocessing images using OpenCV, such as grayscaling and noise removal, can improve OCR results.
Conclusion
We extracted the table data in the image with img2table and Tesseract and convert them to pandas Dataframe. This method is hard to use when accuracy is required, but on the other hand, it may be possible to quickly obtain the overall picture. We would like to continue trying it.