Extract table data from image with MPLUG-DOCOWL2
Improve accuracy
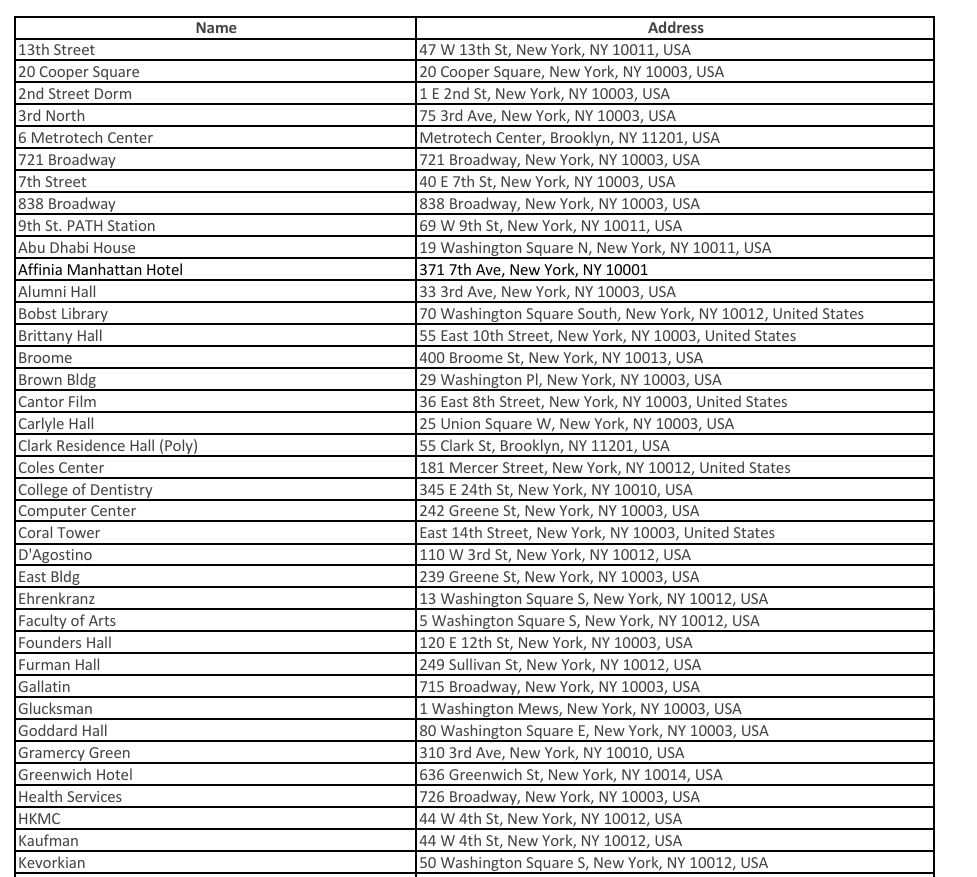
In the previous article, I used Tesseract for OCR, analyzed images using img2table, and converted the table data in the image to CSV. However, I was not able to fully analyze the table_eng.jpg by img2table. For example, the address "721 Broadway" became "[721 Broadway, New York, NY 10003, USA" which contained unnecessary "[".
{kind=link}
While it is possible to improve that, I searched for a more general-purpose method to improve accuracy and found something called MPLUG-DOCOWL2, so I tried it.
Features of MPLUG-DOCOWL2
MPLUG-DOCOWL2 is a next-generation multimodal AI model that can efficiently and accurately analyze high-resolution multi-page documents. It solves the problems that traditional OCR (Optical Character Recognition)-based analysis methods have, and can obtain analysis performance and efficiency.
PLUG-DOCOWL2 learns the complex relationship between text information and visual features by learning from a large dataset, and is able to capture text as part of the visual features.
A typical LLM learns the structure and meaning of language from text data, but cannot understand the meaning from visual information alone. However, by integrating visual features and text information, MPLUG-DOCOWL2 enables the LLM to understand the meaning of text in an image based on context.
For more information about PLUG-DOCOWL2, please refer to the following page:
Analyzing table data using MPLUG-DOCOWL2
Now, let's use MPLUG-DOCOWL2 to analyze table data.
You need to upload the file table_eng.jpg that you used when testing img2table to the test folder beforehand.
import torch
from transformers import AutoTokenizer, AutoModel, BitsAndBytesConfig
import gc
import os
from icecream import ic
class DocOwlInfer():
def __init__(self, ckpt_path):
self.tokenizer = AutoTokenizer.from_pretrained(ckpt_path, use_fast=False)
self.model = AutoModel.from_pretrained(
ckpt_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto'
)
self.model.init_processor(
tokenizer=self.tokenizer,
basic_image_size=504,
crop_anchors='grid_12'
)
def inference(self, images, query):
messages = [{'role': 'USER', 'content': '<|image|>'*len(images)+query}]
answer = self.model.chat(messages=messages, images=images, tokenizer=self.tokenizer)
return answer
docowl = DocOwlInfer(ckpt_path='mPLUG/DocOwl2')
images = [
'./test/table_eng.jpg',
]
def infer_document(docowl, images, query):
if docowl is not None:
print("\nStart...")
return docowl.inference(images, query=query)
else:
print("Failed to initialize docowl")
return None
Now we are ready to ask questions to the test image. First, let’s ask for the address, which was returned with unnecessary "[" when using img2table.
query = "The address of 7th Street" # @param
infer_document(docowl, images, query)
ic| prompt: 'USER: <img 1><|image|>The address of 7th Street ASSISTANT:'
Start...
40 E 7th St, New York, NY 10003, USA
It shows no unnecessary characters and gives me the perfect answer. Great.
Now, let's try to extract the entire table data. At first, I tried to output it in CSV format, but Name and Address were concatenated with a line break, so I couldn't make it into a row record. So, I'll try to output the table data in JSON format.
query = "load all row-wised record in a grid and convert to JSON" # @param
infer_document(docowl, images, query)
ic| prompt: ('USER: <img 1><|image|>load all row-wised record in a grid and convert to '
'JSON ASSISTANT:')
Start...
{'title': 'Name', 'pages': 1, 'data': [{'title': '13th Street', 'page': '1', 'address': '47 W 13th St, New York, 10011, USA'}, {'title': '20 Cooper Square', 'page': '1', 'address': '20 Cooper Square, New York, 10003, USA'}, {'title': '2nd Street Dorm', 'page': '1', 'address': '1 E 2nd St, New York, 10003, USA'}, {'title': '3rd North', 'page': '1', 'address': '75 3rd Ave, New York, 10003, USA'}, {'title': '6 Metrotech Center', 'page': '1', 'address': 'MetroTech Center, Brooklyn, NY 11201, USA'}, {'title': '721 Broadway', 'page': '1', 'address': '721 Broadway, New York, 10003, USA'}, {'title': '7th Street', 'page': '1', 'address': '40 E 7th St, New York, 10003, USA'}, {'title': '9th St. PATH Station', 'page': '1', 'address': '69 W 9th St, New York, 10011, USA'}, {'title': 'Abbie Dabhi House', 'page': '1', 'address': '19 Washington Square N, New York, 10011, USA'}, {'title': 'Affinia Manhattan Hotel', 'page': '1', 'address': '371 7th Ave, New York, 10001, USA'}, {'title': 'Alumni Hall', 'page': '1', 'address': '33 3rd Ave, New York, 10003, USA'}, {'title': 'Bobst Library', 'page': '1', 'address': '70 Washington Square South, New York, 10012, United States'}, {'title': 'Brittany Hall', 'page': '1', 'address': '55 East 10th Street, New York,
The JSON is output, but it is cut off halfway. At this point, I've only touched the chat interface, but if there are other interfaces, I might be able to fully extract the table data in the image.
If you want to try the above code on Google Colab, please click here. However, the GPU required A100. So, you can't try it without paying.
Conclusion
I tried to extract table data from an image using MPLUG-DOCOWL2. Looking at the results of the first query for this test image, it seems to be more accurate than img2table. The above code requires a certain type of GPU, so it's not something you can try easily, but if you want more accuracy than img2table, I think it's an option.